
In the era of digital transformation, the capacity to manage and analyze high-dimensional data has become critical for businesses across industries. Vector databases are emerging as a powerful solution, enabling efficient data retrieval and storage for machine learning and AI applications. By utilizing vector embeddings, these databases excel in similarity search capabilities, making them ideal for advanced recommendation systems and natural language processing tasks. With a focus on performance optimization and scalability, vector databases are positioning themselves as essential tools for handling big data in real-time applications.
This blog dives into the key concepts and trends surrounding vector databases.
What is a Vector Database?
A vector database is a specialized data management system designed to handle and store vector embeddings—numerical representations of data points in a high-dimensional space. Unlike traditional databases, which typically store structured data, vector databases are optimized for unstructured data often used in machine learning and data science.
The primary function of a vector database is to facilitate similarity search—a process that identifies items with similar characteristics based on their vector embeddings. This capability allows businesses to implement advanced applications like personalized recommendations and content-based search functionalities.
In essence, vector databases serve as robust data storage solutions, enabling efficient data retrieval and processing. They are particularly useful in scenarios involving multi-dimensional queries, where traditional databases may struggle to yield quick results. As a result, vector databases have become increasingly popular among organizations looking to harness the power of AI applications and offer enhanced user experiences.
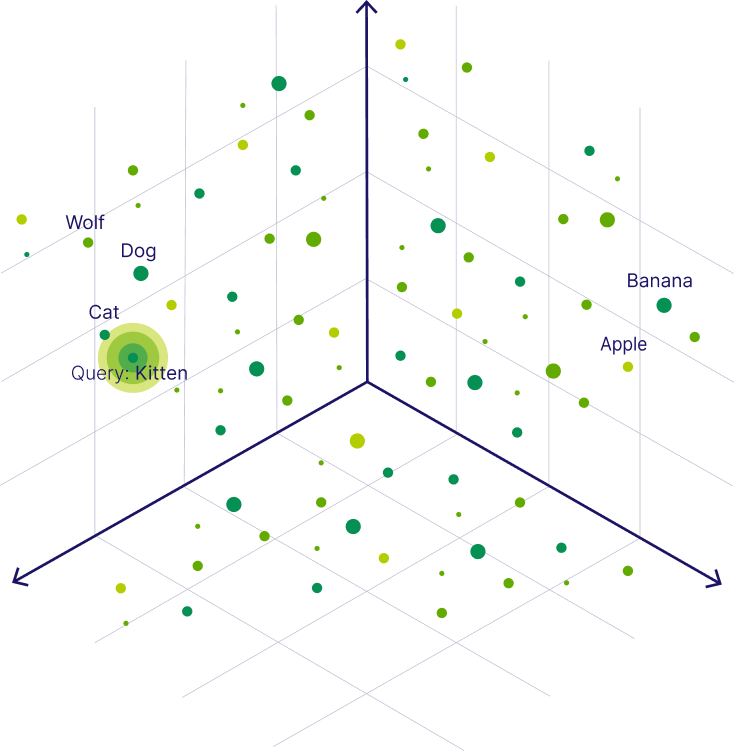
(Source: https://weaviate.io/blog/what-is-a-vector-database)
Key Concepts Behind Vector Databases
To understand the power of vector databases, it’s essential to explore some key concepts that underpin their functionality.
Vector Embeddings are central to vector databases, as they transform various forms of data, such as text, images, and audio, into numerical representations that algorithms can effectively process. This transformation is crucial for applications in natural language processing and machine learning, enabling more nuanced and efficient data handling.
Another critical aspect is similarity search, which leverages the geometric properties of high-dimensional data. By employing optimized search algorithms, vector databases can find items that are similar to a given query almost instantaneously, making them ideal for recommendations and personalized content delivery.
Scalability is another significant advantage; as data grows, vector databases can efficiently manage vast amounts of information without sacrificing performance. This characteristic is vital in today’s world of big data, where companies need to process information in real-time to remain competitive.
Overall, understanding these concepts is key to leveraging the full potential of vector databases in various applications across industries.

(Source: https://www.salesforce.com/blog/vector-database/)
Underlying Technology
Vector databases are built on several advanced technologies that enable them to efficiently store, retrieve, and process large volumes of high-dimensional data. One fundamental component is sophisticated data structures like KD-trees and Ball Trees, which allow for rapid similarity search operations. By efficiently organizing data points based on their vector embeddings, these structures facilitate quick querying and retrieval.
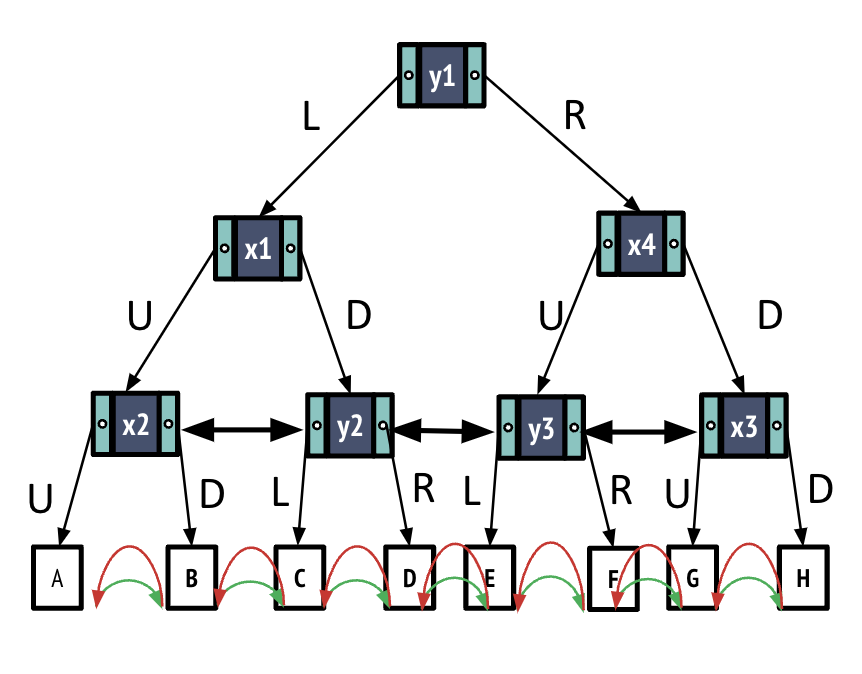
(Source: https://cs186berkeley.net/notes/note19/)
Scalability is a crucial factor, especially as organizations grapple with increasing volumes of big data. Many vector databases are designed to scale horizontally, distributing data across multiple servers to enhance performance during peak loads. This architecture makes them suitable for real-time analytics and processing, allowing businesses to respond quickly to changing user needs.
Integration with AI models further enhances their capability; for example, vector databases are often used alongside machine learning frameworks to streamline data preprocessing and improve predictive accuracy. This synergy between technologies enables more sophisticated AI applications, driving digital transformation across sectors.
Use Cases for Vector Databases
Vector databases find applications across a variety of industries, thanks to their ability to manage high-dimensional data and facilitate rapid data retrieval. One major use case is in recommendation systems. Companies like Amazon and Netflix leverage vector databases to analyze customer behavior and preferences, enabling personalized product and content suggestions.
Another significant application is in natural language processing. By converting textual data into vector embeddings, businesses can implement chatbots and virtual assistants that understand and respond appropriately to user queries.
Additionally, vector databases are instrumental in image retrieval systems, allowing quick searches for images based on visual similarity. Companies in fields such as healthcare also utilize these systems for analyzing medical images, enhancing diagnostic capabilities and decision-making processes.
Overall, the diverse use cases illustrate how vector databases enhance various business functions and contribute significantly to digital transformation efforts.
Comparison with Traditional Databases
When comparing vector databases with traditional databases, significant differences in performance and functionality become apparent. Traditional databases, such as SQL and NoSQL, excel in handling structured data but often struggle with high-dimensional data and conducting efficient similarity searches.
In contrast, vector databases are specifically engineered for scenarios requiring rapid data retrieval based on vector embeddings. They provide advanced capabilities vital for applications like recommendation systems and real-time analytics. Their unique architecture allows for better scalability and performance optimization, making them more suitable for modern data-driven applications where speed and accuracy are paramount.
The Future of Vector Databases
The future of vector databases is promising, driven by advancements in machine learning and AI applications. As organizations increasingly rely on real-time analytics to make data-driven decisions, the demand for efficient storage and processing of high-dimensional data will continue to grow.
Emerging technologies, such as quantum computing and edge computing, may enhance the capabilities of vector databases even further, allowing for faster data processing and improved scalability. Additionally, open-source vector databases are gaining traction, fostering innovation and collaboration within the data community. As digital transformation accelerates, vector databases will play a crucial role in shaping the future landscape of data management and retrieval.
Latest Industry Trends
The landscape of vector databases is rapidly evolving, with several key trends shaping their adoption and development. One significant trend is the growing emphasis on open-source vector databases, which are making advanced data management technologies more accessible to businesses of all sizes. This shift promotes innovation and collaboration in the developer community.
Additionally, companies are increasingly implementing real-time analytics to enhance customer experiences and operational efficiency. The integration of vector databases with existing data infrastructures is also becoming a priority, allowing for seamless data flow and improved performance optimization. As industries continue to adopt AI-driven solutions, the role of vector databases in enhancing recommendation systems will become even more critical.
Challenges and Limitations
Despite their advantages, vector databases face several challenges. One significant limitation is data preprocessing, as transforming raw data into vector embeddings can be time-consuming and require substantial computational resources. Additionally, managing high-dimensional data introduces complexities in maintaining data quality and ensuring effective similarity search results.
There is also the need for specialized knowledge to optimize these systems, which can pose barriers for organizations lacking expertise in machine learning and data science. Therefore, businesses must weigh these challenges against the benefits when implementing vector databases.

(Source: https://www.scalablepath.com/back-end/vector-databases)
In summary, vector databases represent a transformative approach to data management, especially for applications requiring real-time analytics, machine learning, and efficient data retrieval.
As the demand for processing high-dimensional data grows, businesses that leverage these powerful tools will be better positioned to drive innovation and enhance user experiences.



